什麼是機器學習 ?
“A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.”
Tom Mitchell(1998)
簡單來說,機器學習就是讓電腦根據歷史資料(Experience),建立可以被用來對新進資料進行預測或分類等功能(Task)的數學模型。而我們就是藉由評估預測與實際值之間的誤差(Performance),來為各個數學模型進行排名。
舉例來說,我們可以利用程式對一組包含該房屋坪數與售價的資料進行學習,然後對另一組僅有房屋坪數的資料去預測它的售價。
在上面這個例子中
- 資料(Experience) 就是一開始那組(包含坪數與售價)用來建立數學模型的資料
- 任務(Task) 則是預測另一組房屋的售價
- 評估(Performance) 則是預測售價與實際售價之間的誤差
- 隨著資料數目的增加,誤差會變得更小
但如果一個問題,有一個明確且能夠描述的規則,可以使得任務達成完美的零誤差,那麼該問題就不需要應用機器學習。
機器學習的類別
一般而言,機器學習可以被分類為三種主要形式 : 監督式學習(Supervised learning), 非監督式學習(Unsupervised learning)和增強式學習(Reinforcement learning)。
- 監督式學習
- 將資料配適到某個任意類型的函數,需要一些事先標記過的訓練資料
- 可以進一步地再區分為分類(Classification)與迴歸(Regression)。
- 分類
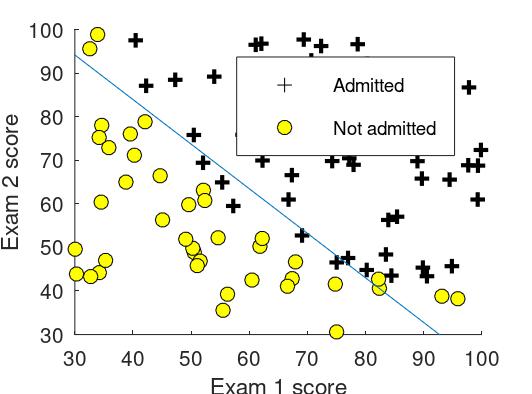 預測離散(0或1)的標籤,藉由繪製一條(不一定線性)邊界線,將資料區分成兩種狀態
預測離散(0或1)的標籤,藉由繪製一條(不一定線性)邊界線,將資料區分成兩種狀態 - 迴歸
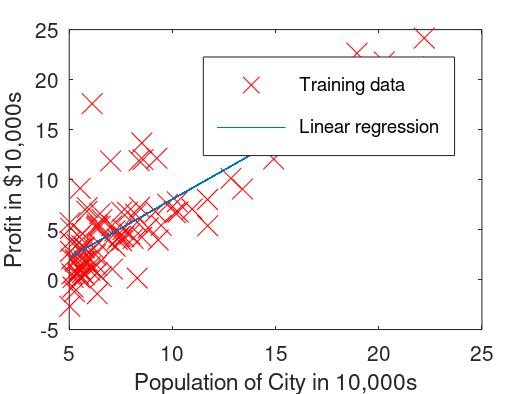 預測連續性的標籤,透過讓程式去觀察資料分布趨勢,繪製一條距離各資料點總和最小的線,去預測目標值
預測連續性的標籤,透過讓程式去觀察資料分布趨勢,繪製一條距離各資料點總和最小的線,去預測目標值
- 分類
- 非監督式學習
- 針對無任何標籤的資料找出資料特性
- 可以進一步再區分為集群(Clustering)與降維(Dimensionality Reduction)
- 集群
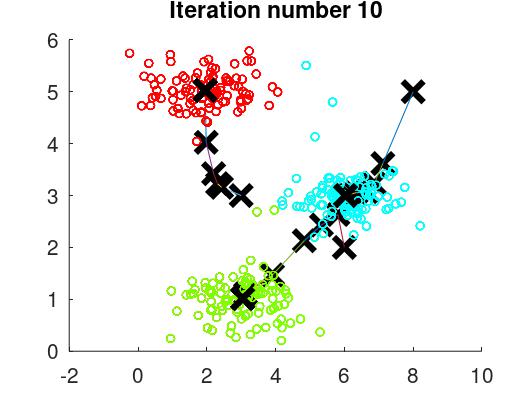 從未建立標籤的資料中推理標籤,藉由不停地更改集群中心,將資料自動的指定到某個數目的離散群組
從未建立標籤的資料中推理標籤,藉由不停地更改集群中心,將資料自動的指定到某個數目的離散群組 - 降維
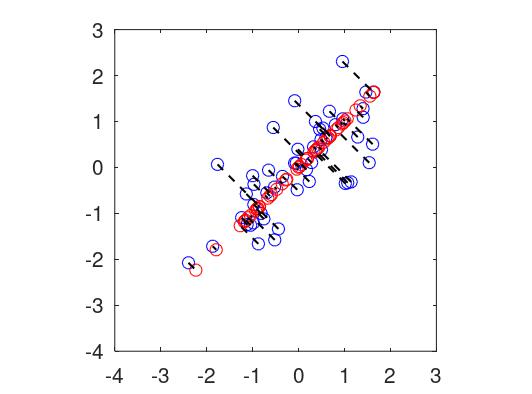 在大致保留重要特徵的前提下,藉由數學投影等技巧,將處於高維空間的資料,順利地轉換到低維空間中
在大致保留重要特徵的前提下,藉由數學投影等技巧,將處於高維空間的資料,順利地轉換到低維空間中
- 集群
參考資料
- Python資料科學學習手冊
- 初探機器學習:使用Python
- 新手村逃脫!初心者的 Python 機器學習攻略(iT邦幫忙鐵人賽系列書)
- Coursera Machine Learning Class